编译原理
程序设计语言是向人以及计算机描述计算过程的记号。例如我们所知道的这个世界依赖于程序设计语言,因为在所有计算机上运行的所有软件都是用某种程序设计语言编写的。但是,在一个程序可以运行之前,它首先需要被翻译成一种能够被计算机执行的形式,完成这项翻译工作的软件系统就是编译器。编译器可以将某种语言(源语言)编写的程序翻译成一个等价的用另外一种语言编写的程序。
编译器能够把源程序映射为语义上等价的目标程序,这个过程可以由两部分组成: 分析部分和综合部分;
- 分析部分(前端):把源程序分解成为多个组成要素,并在这些要素之上加上语法结构。然后使用这个结构来创建该源程序的一个中间表示。如果分析部分检查出源程序没有按照正确的语法构成,或者语义上不一致,它就必须提供有用的信息,使得用户可以按此进行改正。分析部分还会收集有关源程序的信息,并把信息存放在一个称为符号表的数据结构中。符号表将和中间表示形式一起传送给综合部分。
- 综合部分(后端):根据中间表示和符号表中的信息来构造用户期待的目标程序。
编译过程中顺序的执行了一组步骤。每个步骤把源程序的一种表示方式转换为另一种表示方式。如下图所示

前端
源程序–> 词法分析器 -->记号流(token)–> 语法分析器 -->抽象语法树–> 语义分析器 -->中间表示IR

词法分析器
两种实现方式:
- 手动编码,GCC、LLVM,转移图算法
- 词法生成器自动生成器(lex/flex/jlex)
RE–>NFA–>DFA–>词法分析器代码
中间算法:Thompson算法–子集构造算法–Hopcroft最小化算法
正则表达式RE
声明式规范(正则表达式)–>词法分析器
对于给定的字符集 $ \Sigma = {c1,c2,…,cn} $
归纳定义:
- 空串是正则表达式
- 对于任意的 $ c\in\Sigma $ ,c是正则表达式
- 如果M和N是正则表达式,则以下也是正则表达式
- 选择 $ M|N = {M, N} $
- 连接 $ MM = {mn| m \in M, n \in N } $
- 闭包 $ M* = { \varepsilon, M, MM, MMM, … } $
有限状态自动机FA
输入的字符串–>FA–>{yes, no} 什么样的串可以被接受
- 确定状态有限自动机DFA
- 对任意的字符,最多有一个状态可以转移
- 非确定状态有限自动机NFA
- 对任意的字符,有多个状态可以转移
语法分析器
记号流(token)–> 语法分析器 (语言的语法规则) --> 语法树
语法规则:
上下文无关文法的定义:
- 上下文无关文法(简称 文法 )由终结符号、非终结符号、一个开始符号和一组产生式组成
- 终结符号是组成串的基本符号
- 非终结符号是表示串的集合的语法变量
- 某个非终结符号被指定为开始符号,这个符号表示的串集合就是这个文法生成的语言。按照惯例,首先列出来开始符号的产生式。
- 一个文法的产生式描述了将终结符号和非终结符号组合成串的方法。每个产生式由下列形式组成:
非终结符号 --→ 零个或者多个终结符号与非终结符号组成
selection_statement
: IF ‘(’ expression ‘)’ statement
| IF ‘(’ expression ‘)’ statement ELSE statement;
|
;
语法分析树:过滤掉了推导过程中对非终结符号应用产生式的顺序。语法分析树的每个内部节点表示一个产生式的应用。该内部节点表示一个产生式的应用。该内部节点的标号是此产生式头中的非终结符号A;这个节点的子节点的标号从左到右组成了在推导过程中替换这个A的产生式体。
二义性:如果一个文法可以为某个句子生成多棵语法分析树,那么它就是二义性的;换句话说,二义性文法就是对同一个句子有多个最左推导或多个最右推导的文法。
解决方法:文法的重写
语法分析器的实现方式
- 手工分析–递归下降分析器
- 自动生成器–LL(1)、LR(1)
自顶向下分析:从开始符号出发推导句子
1 | tokens[]; |
需要通道回溯,给分析效率带来问题;实际上编译器必须高效,需要线性时间的算法,因此引出递归下降分析和LL(1)分析;
递归下降分析算法(预测分析)
- 每个非终结符构造一个分析函数;
- 用前看符号指导产生式规则的选择。
自动生成
声明式的规范–>自动生成器(antlr:LL(1)、YACC(Unix)、bison(linux))–>语法分析器
LL(1)分析算法
- 从左(L)向右读入程序,最左(L)推导,采用一个(1)前看符号
- 分析高效(线性时间)
- 错误定位和诊断信息准确
- 有很多开源或商业的生成工具(antlr)
- 基本思想:表驱动的分析算法
- 缺点
- 能分析的文法类型受限
- 往往需要文法的改写
自底向上分析
LR分析算法(移进-规约算法)
- 算法运行高效,有现成的工具可用
- 目前最广泛的一类语法分析器的自动生成器(YACC,bison,CUP,C#yacc等)中采用的算法
- 移进 一个记号到栈顶上,或者
- 规约 栈顶上的n个符号(某产生式的右部)到左部的非终结符
- 对产生式A --> $ \beta 1…\beta n $
- 如果 $ \beta n…\beta 1 $ 在栈顶上,则弹出 $ \beta n…\beta 1 $ ,压入A
- 对产生式A --> $ \beta 1…\beta n $
- 表驱动的LR分析器架构
点记号:为了方便标记语法分析器已经读入了多少输入,我们可以引入一个点记号;
LR(0)分析算法
- 从左(L)向右读入程序,最右®推导,不用前看符号来决定式的选择(0个前看符号)
- 优点:容易实现
- 缺点:能分析的文法有限
SLR分析算法
- 和LR(0)分析算法基本步骤相同
- 仅区别于对归约的处理
- 对于状态i上的项目X-> $ \alpha · $ , 仅对y FOLLOW(X)添加ACTION[i,y]
LR(1)分析算法
- 基于LR(0),通过进一步判断一个前看符号,来决定是否执行规约动作
- X–> $ \alpha · $ 归约,当且仅当y FOLLOW(X)
- 优点
- 有可能减少需要归约的情况
- 有可能去除需要递进-归约冲突
- 缺点
- 仍然有冲突出现的可能
对二义性文法的处理
- 二义性文法无法使用LR分析算法分析
- 有几类二义性文法很容易理解:优先级、结合性、悬空else
历史
YACC是Yet Another Compiler-Compiler缩写,在1975年首先在此基础上做了改进:例如GNU Bison,并移植到其他语言上
Yacc架构
用户代码和yacc声明:可以再接下来的部分使用
%%
语法规则:上下文无关文法
%%
用户代码:用户提供的代码
1 | %{ |
语法制导的翻译
编译器在做语法分析的过程中,除了回答程序语法是否合法外,还必须完成后续工作
- 可能得工作(包括但不限于):类型检查、目标代码生成、中间代码生成。这些后续的工作一般可通过语法制导的翻译完成;
- 给每条产生式规则附加一条语义动作(一个代码片段)
- 语义动作产生式"归约"时执行,即由右部的值计算左部的值,以自底向上的技术为例进行讨论
抽象语法树
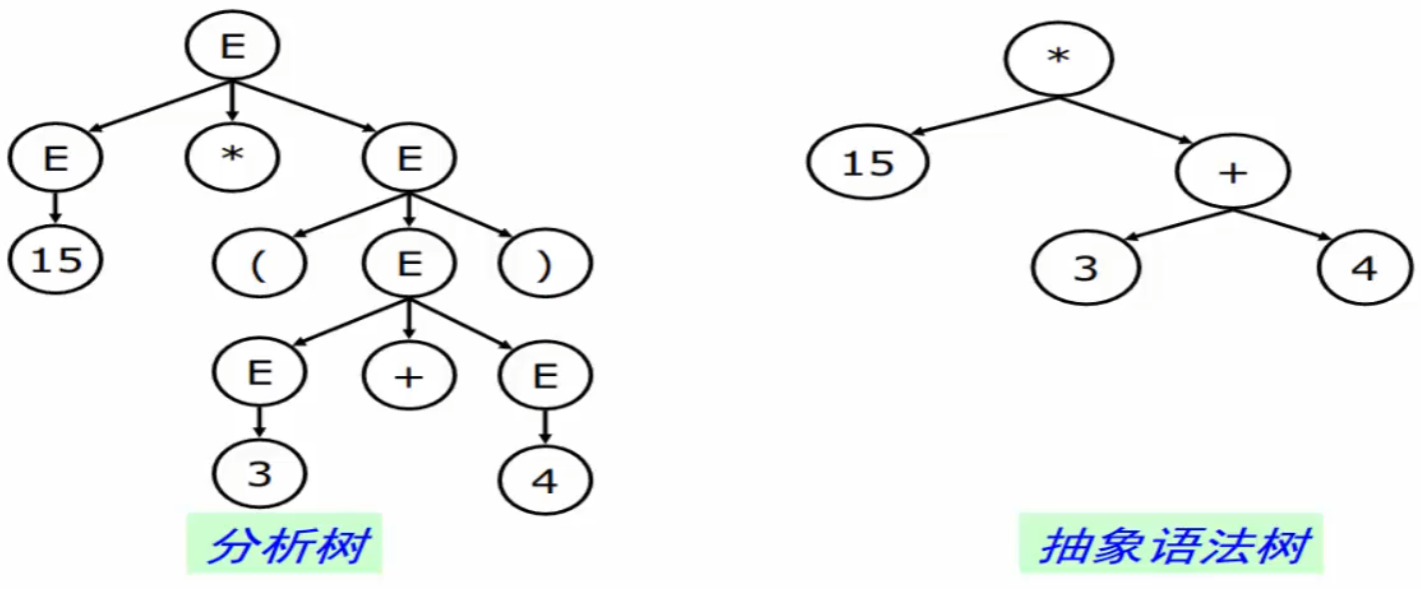
对于表达书而言,编译器只需要知道运算符和运算符(优先级、结合性等已经在语法分析部分处理掉了)。对于语句、函数等语言其他构造而言也一样(例如编译器不关心赋值符号是=还是:=或其他)s
- 具体语法是语法分析器使用的语法
- 必须适合于语法分析,如各种分隔符、消除左递归、提取左公因子等;
- 抽象语法是用来表达语法结构的内部表示
- 现代编译器一般都采用 抽象语法作为前端(词法语法分析)和后端(代码生成)的接口
- 程序一旦被转换为抽象语法树,则源代码即被丢弃,后续阶段只处理抽象语法树
- 所以抽象语法书必须编码足够多的源代码信息,例如:必须编码每个语法结构在源代码中的位置(文件、行号、列号等)
- 为了定义抽象语法树,编译器需要使用实现语言来定义一组数据结构
- 现代编译器一般都采用 抽象语法作为前端(词法语法分析)和后端(代码生成)的接口
语义分析器
语义分析也称为类型检查、上下文相关分析,负责检查程序(抽象语法树)的上下文相关的属性:例如,变量使用前先进行声明、每个表达式都有合适的类型、函数调用和函数的定义一致。
抽象语法树–>语义分析器(根据程序语言的语义进行判断)–>中间代码
语义检查
符号表: 用来存储程序中的变量相关信息(类型、作用域、访问控制信息,处理名字空间)、应为程序中的变量规模会风大,所以必须非常高效,可以使用哈希表(节省时间、O(1)时间)、红黑树(节省空间、 $ O(lgN) $ 时间)等数据结构来实现。
语义分析:类型相容性、错误诊断、代码翻译
中间端和后端
抽象语法树–>代码生成(翻译1–>中间表示1–>翻译2–>中间表示2–>更多的翻译和中间表示)–>汇编
代码生成
负责把源程序翻译成"目标机器"上的代码,两个重要任务:
- 给源程序的数据分配计算资源
- 源程序的数据:全局变量、局部变量、动态分配等
- 机器计算资源:寄存器、数据区、代码区、栈区、堆区
- 根据程序的特点和编译器的设计目标,合理的为数据分配计算机资源,例如:变量放在内存里还是寄存器里?
- 给源程序的代码选择指令
- 源程序的代码:表达式运算、语句、函数等
- 机器指令:算术运算、比较、跳转、函数调用返回
- 用机器指令实现高层代码的语义:等价性、对机器指令集体系结构(ISA的熟悉)
两种不同的ISA上的代码生成技术
- 栈计算机stack
- 历史:在上世纪70年代有很多的栈式计算机,但是因为效率低下已经逐渐退出历史舞台;
- 给栈式计算机生产代码是最容易的;
- 仍然有很多栈式的虚拟机:Pascal P code、java virtual machine(JVM)…
- 寄存器计算机Reg
- 寄存器计算机是目前最流行的机器体系结构之一,效率很高,机器体系结构规整
- 机器基于寄存器架构:
- 经典的有16、32或更多个寄存器,所有操作都在寄存器中进行
- 访存都通过load/store进行,内存不能直接运算
中间代码的地位和作用
为什么划分不同的中间表示?
编译器工程上的考虑
- 阶段划分:把整个编译过程划分为不同的阶段
- 任务分解:每个阶段只处理翻译过程的一个步骤
- 代码工程:代码更容易实现、出错、维护和演进
程序分析和代码优化的需求:两者都和程序的中间表示密切相关,许多优化在特定的中间表示上才可以或才容易进行;
现代编译器中几种常见的重要中间表示(Intermediate Representation,IR):三地址码、控制流图、静态单赋值形式;
在中间表示上做程序分析的理论和技术:控制流分析、数据流分析
-
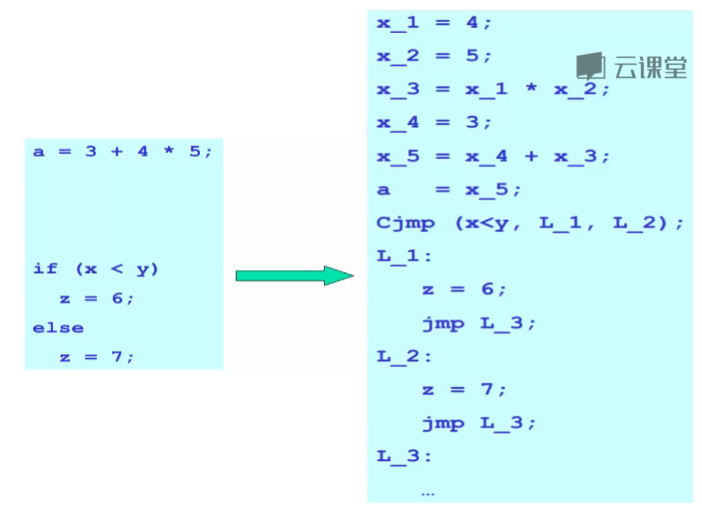
三地址码
-
每条指令有三项操作数,因此叫做三地址码。每条指令通常会有一个目标地址(存储结果的变量或临时变量),以及两个源地址(操作数)。
1
x = y op z
-
给每个中间变量和计算结果命名后没有复合表达式
-
只有最基本的控制流,没有各种控制结构(if、do、for…),只有goto、call等
-
所以三地址码可以看成是抽象的指令集,可以看成是一个通用的RISC
-
程序的控制流信息是隐式的,可以做进一步的控制流分析
-
-
控制流分析
-
是更加精细的三地址码
-
程序的控制流图表示带来了很多好处
- 控制流分析:对于很多程序分析来说,程序的内部结构很重要;经典问题:程序中是否存在循环?
- 可以进一步进行其他分析:例如数据流分析;经典问题:程序第5行的变量x可能的值是什么?

-
现代编译器的早期阶段就会倾向于做控制流分析,方便后续阶段的分析
-
基本块:是一个语句的序列,从第一条执行到最后一条,不能从中间进入和退出(即跳转指令只能出现在最后)
-
控制流图:控制流图是一个有向图G=(V,E);节点V是基本块,边E是基本块之间的跳转关系

-
可以直接从抽象语法树生成:如果高层语言具有特别规整控制流结构的话较容易;也可以先生成三地址码,然后继续生成控制流图:
- 对于像C这样的语言更加合适,包含像goto这样的非结构化的控制流语句;
- 更加通用(阶段划分)
1
2
3
4
5
6
7
8
9
10
11
12
13List_t stms; // 三地址码中所有语句
List_t blocks = {}; //控制流图中的所有基本块
Block_t b = Block_fresh(); //一个初始的空的基本块
scan_stms()
foreach(s in stms)
if (s is "Label L") // s是标号
b.label = L;
else (s is some jump) //s是跳转
b.j = s;
blocks U= {b};
b = Block_fresh();
else // s是普通指令
b.stms U= {s}; -
标准的图论算法都可以用在控制流图的操作上:各种遍历算法、生成树、必经节点结构等等;
-
图节点的顺序有重要的应用:拓扑序、逆拓扑序、近似拓扑序等等;
-
-
数据流分析
- 常量传播优化
- 通过对程序代码进行静态分析,得到关于程序数据相关的保守信息,必须保证程序分析的结果是安全的
- 根据优化的目标不同,需要进行的数据流分析也不同
- 到达定义分析:对每个变量的使用点,有哪些定义可以到达?(即该变量的值是在哪儿赋值的)
- 数据流方程
- 活性分析:在代码生成的讨论中,机器只有有限多个寄存器,寄存器分配优化需要进行活性分析
- 到达定义分析:对每个变量的使用点,有哪些定义可以到达?(即该变量的值是在哪儿赋值的)
代码优化
代码优化是对被优化的程序进行的一种语义保持(程序的可观察行为不能改变)的变换,变换的目的是让程序能够比变换前更小、更快、cache行为更好、更节能等等;
前端优化
-
一般在抽象语法树阶段做优化
-
局部的、流不敏感的
-
常量折叠、代数优化、死代码删除等
-
常量折叠:在编译期间计算表达式的值,可以在整型、布尔型、浮点型等数据类型上进行;容易实现、可以在语法树或者中间表示上进行,通常被实现成公共子函数被其他优化调用;
例如:a=3+5 ==> a=8
例如:if(true&&false) ==>if(false)
必须要很小心遵守语言的语义,例如:考虑溢出或异常 oxffffffff+1==>0 ???
-
代数化简:利用代数系统的性质对程序进行化简
示例:
a = 0+b ==> a = b
a = 1*b ==> a = b
2*a ==> a + a (强度削弱)
2*a ==> a<<1 (强度削弱)
同样必须非常仔细的处理语义,例如:(i - j) + (i - j) ==> i + i - j - j
-
死代码(不可达代码)删除:静态移除程序中不可执行的代码
示例:
if (false)
s1;
else s2; ==> s2;
在控制流图中也可以进行这些优化,但在早期做这些优化可以简单中后端
-
中期优化
-
在中间表示上进行代码优化
-
全局的、流敏感的
-
依赖于具体所使用的中间表示:
-
控制流图(CFG)、控制依赖图(CDG)、静态单赋值形式(SSA)、后续传递风格(CPS)等
-
共同的特点是需要进行程序分析,优化是全局进行的,而不是局部,通用的模式是:程序分析–>程序重写
-
优化的一般模式:

-
-
常量传播、拷贝传播、死代码删除、公共字表达式删除等
-
常量传播:先进行到达定义分析,例如x=1,y=2,z=x+y --> x=1,y=2,z=3
1
2
3
4
5
6
7
8
9//常量传播算法
const_prop(Prog_t p)
//第一个:程序分析
reaching_definition(p)
//第二步:程序改写
foreach(stm s in p: y = x1,...,xn)
foreach(use of xi in s)
if(the reaching def of xi is unique: xi = n )
y = x1,...,xi-1,n,xi+1,...,xn -
拷贝传播: 例如: x=y ;a=x --> a=y
1
2
3
4
5
6
7
8
9//常量传播算法
const_prop(Prog_t p)
//第一个:程序分析
reaching_definition(p)
//第二步:程序改写
foreach(stm s in p: y = x1,...,xn)
foreach(use of xi in s)
if(the reaching def of xi is unique: xi = z )
y = x1,...,xi-1,z,xi+1,...,xn -
死代码删除:需要进行活性分析
1
2
3
4
5
6
7
8//死代码删除算法
dead_code(Prog_t p)
//第一步:程序分析
liveness_analysis(p);
//第二步:程序改写
foreach(stm s in p:y = ...)
if(y is NOT in live_out[s])
remove(s);
-
后端优化
- 在后端(汇编代码级)进行
- 寄存器分配、指令调度、窥孔优化等
Reflection
OS:终于把本科分流后欠下的债还了一部分了。谁懂啊,从计算机专业分流去了大数据后,研究生阶段又跑来搞系统;
参考资源: